
4.1 The Rise of Surveillance Capitalism
Adrian Castillo
“He thought of the telescreen with its never-sleeping ear. They could spy upon you night and day, but if you kept your head, you could still outwit them. With all their cleverness, they had never mastered the secret of finding out what another human being was thinking.”
—George Orwell, Nineteen Eighty-Four (1949)
Figure 3.
The Digital City & Big Brother.

Published 72 years ago, Orwell’s dystopian novel, Nineteen Eighty-Four, warned humanity about sinister technologies of mass surveillance, such as telescreens, devices that predicted our voice-activated speakers like Alexa, security cameras such as Google’s video doorbell Nest Hello, and the microphones embedded in our smartphones, and combined them with our most sophisticated mass communication media, the television. Hence, telescreens can be described as omnipresent eyes, ears, and voices. The twenty-first century is blurring the lines between Orwell’s dystopian fiction and reality. Today technological omnipresence (ubiquity) is accompanied by technological omnipotence (unlimited power), as our current technologies are “controlled by just five global mega-corporations that are bigger than most governments” (Pringle, 2017, para. 1), namely, Apple, Amazon, Facebook, Microsoft, and Google’s parent company, Alphabet. Together, they are known as “Big Tech” or the “Big Five,” and they are conglomerates whose power is threatening our freedom and democracy (Zuboff, 2019a).
It all began in the early 2000s when Google pioneered a new form of “interest-based advertising” (Finkelstein, 2009) called Google AdSense. According to Google, this is a simple way to earn money on publisher’s websites by displaying ads that are automatically targeted to the site content and audience (Google, n.d., how AdSense works section). The explanation provided by Google, although simple, is not transparent since it does not explain how AdSense collects large amounts of personal data for marketing purposes. Let’s see what information Google is tracking, according to Geary (2012):
- time: 06/Aug/2008 12:01:32
- ad_placement_id: 105
- ad_id: 1003
- user id: 0000000000000001
- client_ip: 123.45.67.89
- referral_url: “http://youtube.com/categories”
At first glance, that information may seem incomprehensible, but those pieces tell Google:
- time: the time and date you saw an advert.
- ad_placement_id: the ID of where the advert was seen on the site.
- User id: the unique ID number the cookie has given your browser.
- Client_ip: your country and town/city.
- ad_id: the unique ID of the advert.
- referral_url: what page you were on when you saw the advert.
That is how AdSense collects and scrutinizes our online behavior, but it doesn’t stop there. The “Big Five” use similar practices. Apart from Google, Facebook has high-level systems for data collection, even data about people who have not signed on to the platform (Nielo, 2020). In other words, we believed Facebook predominately collected our status updates, photos, comments, and likes. On the contrary, for Facebook, the most critical information is what we don’t consciously share with the platform: our browsing activities on millions of other websites (Azhar, 2019). The social platform does this by tracking users across the web and behind the scenes with a piece of code called “Facebook Pixel” (John, 2018). This code enables Facebook to know when you accessed a website, including date, time, URL, browser type, and other online behaviors. Then, Facebook can match that data with your Facebook profile and return a version of that data to the website owner. According to Facebook’s VP for Public Policy, Richard Allan, “The cookies and pixels we use are industry standard technologies…” (as cited in Lomas, 2018, para. 5). In fact, cookies are used by 41% of all websites, of which 34.6% use non-secure cookies with unencrypted connections that could become be a security threat (W3Techs, 2021).
In response to the new realities of the internet, Shoshana Zuboff, former Harvard professor, philosopher, and scholar, coined the term “surveillance capitalism.” The term defines the economic system that hijacked the Internet and its digital technologies to commodify human experience and transformed it into data, with the core purpose of monitoring, influencing, and predicting human behavior, which can be analyzed and sold (Zuboff, 2019b).
Professor Zuboff explains “surveillance capitalism.” Please watch.
The Lavin Agency Speakers Bureau. (2019, May 14). What is surveillance capitalism? [Video]. YouTube. https://www.youtube.com/watch?v=fwNYjshqZ10&t=1s
Nevertheless, Zuboff (2019b) clearly states that she is after “the puppet master, not the puppet” (p.30). In other words, surveillance capitalism is not a technology. It is the logic that commands technology to blend commercial goals with technological necessities. The scholar argues that Big Tech firms want people to think that surveillance practices are inevitable expressions of their digital technologies. For example, search engines do not store data, surveillance capitalism does (Zuboff, 2019a). According to Warren (2018), while you can delete your browser history, you won’t be able to delete what is stored in Google’s servers. Furthermore, we must not see digital technologies as tools pre-destined to steal our data, but rather as tools designed by people, artificially made, meticulously calculated. Therefore, we can change their nature through democratic legal regulation.
Big Tech: A Threat to Democracy?
“We can have democracy, or we can have a surveillance society, but we cannot have both” (Zuboff, 2021, para. 1).
Figure 4.
Smartphone control.

Back in 2018, the Cambridge Analytica scandal made headlines when it was revealed how the political research firm stole the Facebook data of millions of Americans before the 2016 election, intending to give Ted Cruz and Donald Trump’s campaign big data tools to compete with Democrats (Detrow, 2018). Cambridge Analytica’s wrongdoings came to light when whistleblower, Christopher Wylie, a Canadian data analytics expert who worked for the firm, told the press: “We exploited Facebook to harvest millions of people’s profiles. And built models to exploit what we knew about them and target their inner demons. That was the basis the entire company was built on” (as cited in Cadwalladr & Graham-Harrison, 2018a, para. 3).
To gather data from Facebook users, Cambridge Analytica used an app called this is your digital life; it featured a personality quiz that recorded the data not only of each person taking the quiz, but crucially, extracted the data of that person’s Facebook friends as well (Cadwalladr & Graham-Harrison, 2018b). As a result, Cambridge Analytica obtained massive datasets that allowed the firm to build personality profiles and segment American voters into categories, such as: “high in conscientiousness and neuroticism,” or “high in extroversion but low in openness,” among other traits (Wade, 2018). Next, the segmentation was used to tailor highly individualized political messages and misinformation campaigns on topics related to immigration, the economy, and gun rights (Wade, 2018).
All of these actions were completed without the knowledge or consent of the American electorate (Cadwalladr, 2019). Consequently, Zuboff (2019b) explains that Cambridge Analytica is the perfect illustration of surveillance capitalism’s tactical approach and its ultimate purpose: “[Surveillance capitalism was] designed to produce ignorance through secrecy and careful evasion of individual awareness” (p. 303).
These events prompted Canadian scholar Taylor Owen (2017) to analyze if Facebook threatens the integrity of Canadian democracy. The scholar explains that Facebook is a potent political weapon, which by means of consumer surveillance and customized information feeds (micro-targeting), can allow buyers such as foreign actors, companies, or politicians to purchase an audience. This scheme may facilitate buyers “to define audiences in racist, bigoted and otherwise highly discriminatory ways” (para. 4). In addition, Owen (2017) explains that even without Facebook’s micro-targeting, much of its content is not accessed for quality or truthfulness, and can therefore manipulate huge audiences with low-quality clickbait information.
The Cambridge Analytica Presentation: A Misleading Pitch?
“They’re not confessing. They’re bragging.”
– The Big Short (2015)
Infamous for manipulating American voters, today Cambridge Analytica has dissolved; however, before the firms’ scandal made headlines, Cambridge Analytica’s CEO, Alexander Nix, was happy to share in a conference how the firm harvested Facebook data from a survey undertaken by “hundreds” of Americans. Nix explains the survey data allowed his firm to “form a model to predict the personalities of every single adult in the United States of America” (Concordia, 2016, 3:42). In addition, Nix describes how the company used psychographic targeting to influence votes through customized messages, including “fear-based messages” (Concordia, 2016, 4:20). Thus, we can say that Alexander Nix exemplifies the very definition of a surveillance capitalist.
Please watch the videos below and answer their respective Google Form questions. The questions are open-ended and there are no wrong answers! Just elaborate your ideas as much as you can. Most importantly, your answers are anonymous and will be used exclusively to improve the content of the present eBook.
[devXnull]. (2018, April 25). CEO Alexander Nix speaks about Cambridge Analytica [Video]. YouTube. https://www.youtube.com/watch?v=UaS8LksPHJs
CBC News. (2018, March 19). Canadian whistleblower Christopher Wylie talks about Cambridge Analytica [Video]. YouTube. https://www.youtube.com/watch?v=MuFRg-CU6Nc
At its core, Facebook is a political tool because we live in the information age. As Zuboff (2021) explains in a recent New York Times article:
In an information civilization, societies are defined by questions of knowledge — how it is distributed, the authority that governs its distribution, and the power that protects that authority. Who knows? Who decides who knows? Who decides who decides who knows? Surveillance capitalists now hold the answers to each question, though we never elected them to govern. This is the essence of the epistemic coup. They claim the authority to decide who knows by asserting ownership rights over our personal information and defend that authority with the power to control critical information systems and infrastructures. (para. 3)
From Online to Onlife
“Technology has outmatched our brains, diminishing our capacity to address the world’s most pressing challenges. The advertising business model built on exploiting this mismatch has created the attention economy. In return, we get the ‘free’ downgrading of humanity” (Harris, 2019, para. 17).
Figure 5.
Social Media may lead to non-substance addiction.

In the post-industrial information age, Zuboff argues that the cause of our digital issues is the accumulation of economic and knowledge power in the hands of big tech. Conversely, a former design ethicist at Google, Tristan Harris, argues that the source of our problems is how business models in technology seek to exploit our minds, more precisely our limited attention spans. According to Harris (2019), even if we fixed the privacy issues whereby big tech firms collect and monetize from our personal data, we would still have to face the fact that our technology can easily outmatch our brains ( i.e. our addiction to online social validation, our love for “likes, our obsession with scrolling through news feeds”). They would all persist and carry on with destroying our attention spans. Indeed, in a recent survey across Canada, over 75% of respondents indicated that they spend “at least 3-4 hours online every day, and 15 percent are spending more than eight hours online per day” (Canadian Internet Registration Authority, 2020).
Back in 2013, Harris made a 141-slide deck entitled A Call to Minimize Distraction & Respect Users’ Attention, in which he explains his goal is to create a new design ethic that aims to minimize distraction; otherwise, Harris explains, our technologies will systematically worsen our human shortcomings, including:
- “Bad Forecasting” (a.k.a. “that won’t take long”) Harris (2013) illustrated that humans are bad at estimating how long a task is going to take. For example, in a Facebook notification alerting you that you had been tagged in a photo, the label would say something like “see your photo.” Harris suggests the label should read “spend next 20 minutes on Facebook” (slide, 46). Thus, Harris recommends that technology should help users forecast the consequences of certain actions, so they can make informed decisions.
- “Intermittent variable rewards”’ (a.k.a. slot machines) Just like playing in a casino, Harris (2013) suggests that intermittent rewards are the hardest to stop, and easily become addictive. As an illustration, we constantly refresh an app like Twitter or Facebook to find “reward” in new content.
- “Loss aversion (a.k.a. “the fear of missing out”) Harris (2013) states that what is stopping us from turning off our alerts or phone notifications is the fear of missing an important event. We think that at any moment we could receive a message saying “Hey, a nuclear bomb just exploded over your house” (slide, 67). Harris says we should have the option to disconnect.
- “Fast and slow thinking” (a.k.a. Mindful vs Mindless behavior) According to Harris (2013), people make different decisions when they have time to pause and reflect vs when they react impulsively. If technology is made “too frictionless” we stop thinking (e.g. when scrolling is frictionless we can flick for hours). Harris (2013) suggests creating “speed bumps” that provide us time to think.
- “Stress and altered states” (a.k.a. “I am not in the best state of mind to decide”) Finally, the tech ethicist warns us that technology is affecting our overall health through anticipation of alerts, which creates stress, and a cascade effect of physiological responses. Overall, these human vulnerabilities enable big tech to steal our time.
Although Zuboff and Harris may disagree on what is cause and what is consequence (economic system vs. human psychology), both arrive at the same conclusion: big tech has become a threat to human agency and wellbeing.
Terms of Service: Click to Agree with What?
Terms of Service are the legal agreements or “contracts” between a service provider and the person who wants that service (LePan, 2020). The great majority of people do not read these unescapable online “contracts,” and there is a good reason for that.
Figure 6.
Drowning in paperwork.

According to LePan, (2020), the average person would need almost 250 hours to read all digital contracts properly. Likewise, Zuboff (2019b) states that many websites push users to agree with terms of service just for browsing a website. In addition, many terms of service can be modified by service providers unilaterally at any time, without user awareness. To make things worse, terms of service typically involve other companies and third parties. Zuboff (2019b) explains that a recent study by academics from the University of London shows that to enter the ecosystem of Google’s smart home devices (Nest Home), users may need to read a thousand contracts. LePan (2000) offers the following table calculating how much time it would take to read the terms of services different companies provide (according to their word count and based on a reading speed of 240 words per minute):
Table 1
Terms of service reading time
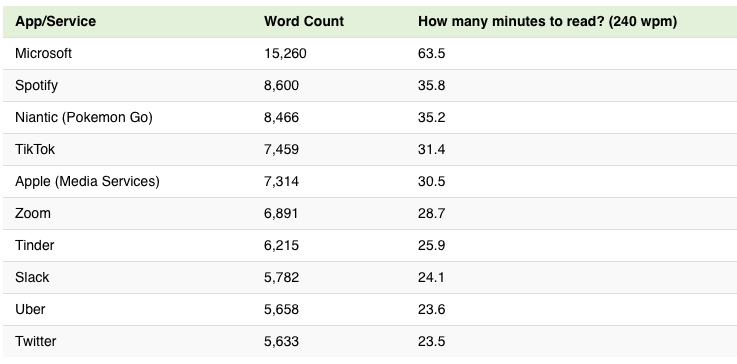
Consequently, we can see how terms of services place a heavy reading load on consumers. Terms of service are voluminous, non-negotiable documents; by design, they don’t encourage any scrutiny. As an illustration, imagine having to read 50-printed pages when entering a bowling alley, which is the equivalent of Microsoft’s 15,000-word terms of service.
Activity Time!
- Please visit the website “Terms of Service. Didn’t Read.” It will provide you with summaries of companies’ terms of service, and an overall rating of their quality from the user’s standpoint.
- Identify a company or service to which you already subscribe.
- Based on the summaries from “Terms of Service. Didn’t Read,” follow the instructions in the Google Form
As we have seen in this section, surveillance capitalism is a potentially dangerous economic logic. In the next chapter, we will learn some tactics to counter surveillance capitalism.
